30分钟入门hadoop
本文主要是通过docker快速搭建hadoop集群,然后快速尝试hdfs, map reduce的基本功能,揭开Hadoop的神秘面纱。
Hadoop介绍
先讲解一下hadoop的基本概念, 想快速尝试Hadoop的同学可以跳过这个章节直接到快速开始Hadoop.
Hadoop是一个软件集合
Hadoop不是一个软件,是一个软件的集合, 一个分布式大数据存储管理软件的集合, hdfs + map reduce是hadoop基础的分布式文件储存和分布式计算功能。 下图是hadoop的架构图.
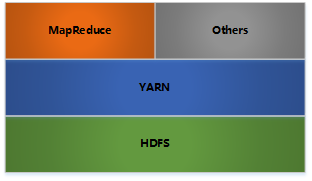
hadoop是一个分布式计算+分布式文件系统,前者其实就是MapReduce,后者是HDFS。后者可以独立运行,前者可以选择性使用,也可以不使用。
HDFS是根基
HDFS是Hadoop的根基, 是一个分布式文件储存系统. HDFS的架构如下:
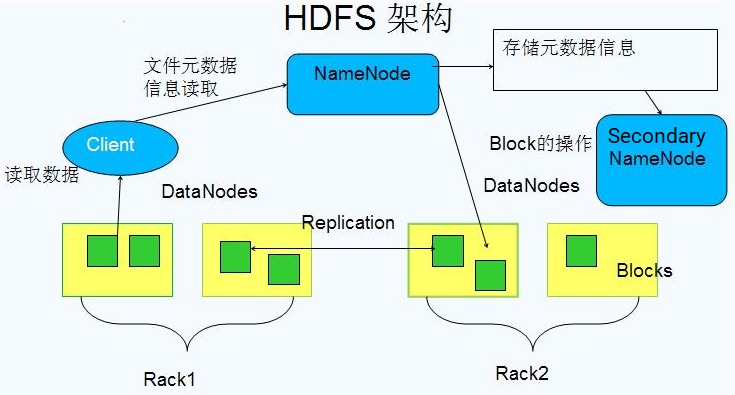
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
YARN是管家,是Map-Reduce框架
YARN是Hadoop集群的资源管理系统, 也是Map Reduce框架的基础, Map Reduce API构建在这只是。Yarn 的全称是 ** Yet Another Resource Negotiator**,意思是“另一种资源调度器”.
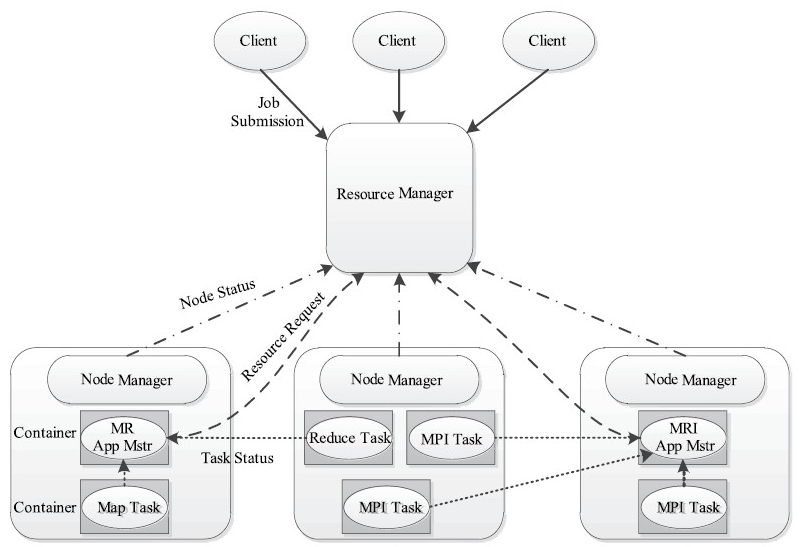
YARN包含两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。
下图描述了YARN的基本组成结构,YARN主要由ResourceManager、NodeManager、ApplicationMaster(图中给出了MapReduce和MPI两种计算框架的ApplicationMaster,分别为MR AppMstr和MPI AppMstr)和Container等几个组件构成。
Map reduce, hive, hbase 是上层应用
在hdfs之上, Hadoop围绕分布式大数据有非常丰富的功能或者插件,解决大数据不同方面的问题。 基于hdfs之上的所有应用都由yarn来管理。
特点:
hive把数据文件加载进来作为一个hive表(或者外部表),它支持类似sql语句的功能,你可以通过该语句完成分布式环境下的计算功能,hive会把语句转换成MapReduce,然后交给hadoop执行。这里的计算,仅限于查找和分析,而不是更新、增加和删除。
hbase只是利用hadoop的hdfs帮助其管理数据的持久化文件(HFile),它跟MapReduce没任何关系。它使用的是nosql,或者说是列式结构,从而提高了查找性能,使其能运用于大数据场景,这是它跟MapReduce的区别。
优势:
hive的优势是对历史数据进行处理,用时下流行的说法是离线计算,因为它的底层是MapReduce,MapReduce在实时计算上性能很差。
hbase的优势在于实时计算,所有实时数据都直接存入hbase中,客户端通过API直接访问hbase,实现实时计算。
总结:
hadoop是hive和hbase的基础,hive依赖hadoop,而hbase仅依赖hadoop的hdfs模块。
hive适用于离线数据的分析,操作的是通用格式的(如通用的日志文件)、被hadoop管理的数据文件,它支持类sql,比编写MapReduce的java代码来的更加方便,它的定位是数据仓库,存储和分析历史数据。
hbase适用于实时计算,采用列式结构的nosql,操作的是自己生成的特殊格式的HFile、被hadoop管理的数据文件,它的定位是数据库,或者叫DBMS。
补充:
hive可以直接操作hdfs中的文件作为它的表的数据,也可以使用hbase数据库作为它的表。
快速开始Hadoop
大部分人在尝试hadoop的时候被复杂的环境搭建给阻挡住了。今天就教给大家一个通过docker-compose搭建hadoop集群,运行hadoop hello world的方法,让大家在整体上有一个简单的概念。
Docker搭建Hadoop集群
git clone https://github.com/younthu/docker-hadoop
进入docker-hadoop目录,然后启动集群:
docker-compose up -d
docker会拉取远程image然后搭建一个包含一个resourcemanager,nodemanger, 一个namenode(管理文件元数据), 3个datanode(存储文件的块),一个historyserver的集群。
你可以通过docker ps查看集群启动情况
>docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c31471050adc bde2020/hadoop-historyserver:2.0.0-hadoop3.1.1-java8 "/entrypoint.sh /run…" About a minute ago Up About a minute (healthy) 8188/tcp historyserver
68e6ee7a326f bde2020/hadoop-resourcemanager:2.0.0-hadoop3.1.1-java8 "/entrypoint.sh /run…" About a minute ago Up About a minute (healthy) 0.0.0.0:8089->8088/tcp resourcemanager
eaaf19dae58a bde2020/hadoop-nodemanager:2.0.0-hadoop3.1.1-java8 "/entrypoint.sh /run…" About a minute ago Up About a minute (healthy) 8042/tcp nodemanager1
c1bfbc885135 bde2020/hadoop-datanode:2.0.0-hadoop3.1.1-java8 "/entrypoint.sh /run…" About a minute ago Up About a minute (healthy) 9864/tcp datanode2
79a3b6c80c6d bde2020/hadoop-datanode:2.0.0-hadoop3.1.1-java8 "/entrypoint.sh /run…" About a minute ago Up About a minute (healthy) 9864/tcp datanode3
6123cb7298fe bde2020/hadoop-datanode:2.0.0-hadoop3.1.1-java8 "/entrypoint.sh /run…" About a minute ago Up About a minute (healthy) 9864/tcp datanode
4bb9d1ee24f4 bde2020/hadoop-namenode:2.0.0-hadoop3.1.1-java8 "/entrypoint.sh /run…" About a minute ago Up About a minute (healthy) 0.0.0.0:9870->9870/tcp namenode
用浏览器打开http://localhost:9870, 从namenode节点查看系统情况。
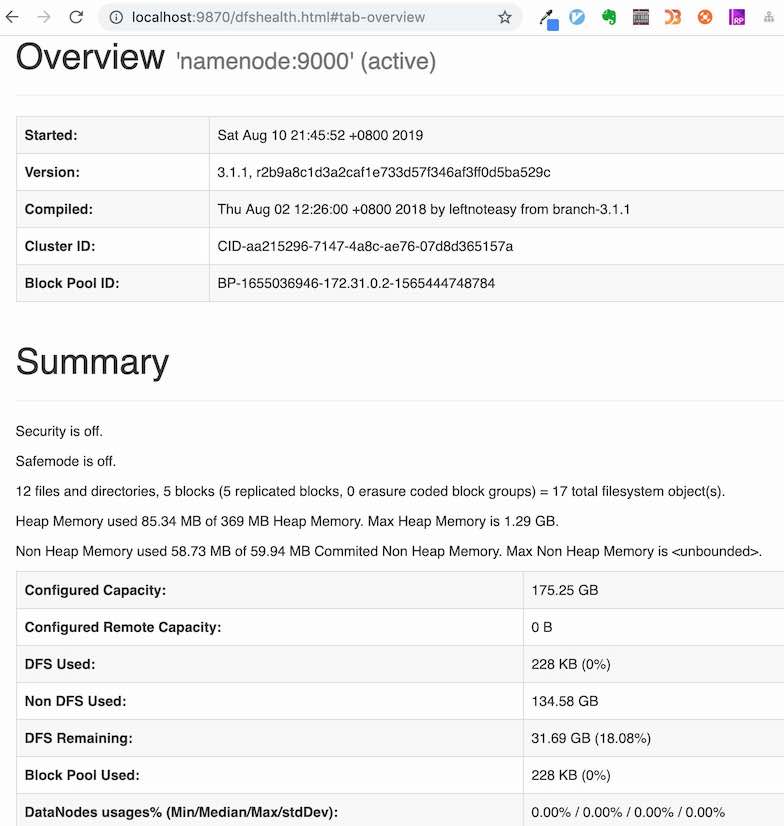
测试Hadoop集群
现在我们通过运行经典的WordCount程序来测试我们的hadoop集群。
WordCount的源代码在wordcountv2.0, jar包已经随源码迁出在docker-hadoop/目录下,。
- 进入namenode:
docker exec -it namenode bash - 创建两个txt文件作为WordCount的输入.
$ mkdir input $ echo "Hello World" >input/f1.txt $ echo "Hello Docker" >input/f2.txt - 在HDFS创建input目录
$ hadoop fs -mkdir -p input # `hadoop fs`是一个通用的接口,会被翻译成`hdfs dfs`, 所以上面这句等效于 # hdfs dfs -mkdir -p input - 把本地文件上传到hdfs
$ hdfs dfs -put ./input/* input - 把
WordCount程序拷贝到namenode容器里面去docker cp ./hadoop-mapreduce-examples-2.7.1-sources.jar namenode:hadoop-mapreduce-examples-2.7.1-sources.jar - 在
namenode上运行WordCount程序root@namenode:/# hadoop jar hadoop-mapreduce-examples-2.7.1-sources.jar org.apache.hadoop.examples.WordCount input output - 打印
WordCount的输出root@namenode:/# hdfs dfs -cat output/part-r-00000 World 1 Docker 1 Hello 2
至此,你已经成功的运用Hadoop集群跑了一个mapreduce应用!
你可以通过目录docker-compose down -v来删除所有的容器和数据卷。
探索集群
- Resource Manager, http://localhost:8089.
- Name Node, http://localhost:9870. 文件管理系统。这地方可以浏览hadoop文件目录,然后可以下载文件(下载的时候文件下载路径里ip要换成localhost).
- Node Manager, http://localhost:8042. ResourceManager在每台机器上的代理,负责容器管理,并监控它们的资源使用情况,以及向ResourceManager/Scheduler提供资源使用报告
- Datanode1, http://localhost:9864.文件储存节点。 这个地址可以用来下载hadoop文件, eg, input/f1.txt
- Datanode2, http://localhost:9865. 和Datanode1一样。
- Datanode3, http://localhost:9866. 和datanode1一样。
