Stable Diffusion
欢迎转载,请支持原创,保留原文链接:blog.ilibrary.me
玩了几个月的Stable Diffusion, 做个笔记,方便后面查阅。
本地搭建Stable Diffusion
- WebUI 做图片
- Comfy UI + AnimateDiff做动画
- https://github.com/AbdBarho/stable-diffusion-webui-docker/wiki/Setup, docker 启动,
docker compose --profile auto-cpu up --build数据加载在./data目录下,可以把模型下载到./data/models下面
- aaa
- bbb
开源模型Stable Diffusion使用
默认的模型生成的图片特别难看,非常吓人。需要手动下载一些风格模型才能生成好看的图片。
Stable Diffusion微调/LORA
核心知识点如下:
- Diffusion 模型是图像生成领域中应用最广的生成式模型之一,除此之外市面上还有生成对抗模型(GAN)、变分自动编码器(VAE)、流模型(Flow based Model)等其他模型,它们都是基于深度学习为训练方式的模型。
- 这篇文章把Stable Diffusion基础知识介绍得不错. 6000字干货!超全面的Stable Diffusion学习指南:初识篇
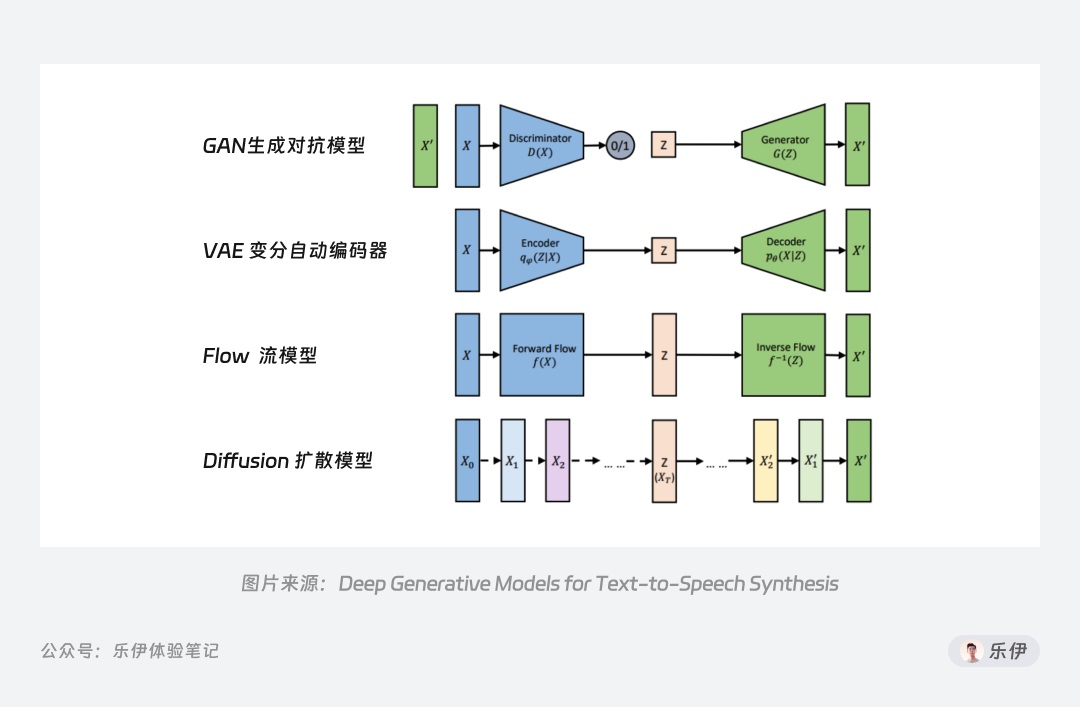
- 这篇文章把Stable Diffusion基础知识介绍得不错. 6000字干货!超全面的Stable Diffusion学习指南:初识篇
- Stable Diffusion开源,免费,可以自由控制内容的生成。是由Stability AI出品。
- ClipText 文本编码器:用于解析提示词的 Clip 模型
- Diffusion 扩散模型:用于生成图像的 U-Net 和 Scheduler
- U-Net是神经网络. U-Net 原本是用于生物医学图像分割的神经网络模型,因为工作结构像一个 U 型字母,因此被称为 U 型神经网络训练模型
- Scheduler是采样算法.在训练扩散模型过程中,可以采用不同的算法来添加噪音,而 Scheduler 就是用来定义使用哪种算法来运行程序,它可以定义降噪的步骤、是否具备随机性、查找去噪后样本的算法等,因此它又被称为采样算法。
- VAE 模型:用于压缩和恢复的图像解码器. 最后的解码器 VAE,全称是 Variational Auto Encoder 变分自动编码器。简单来说,它的作用就是将高维数据(像素空间)映射到低维空间(潜空间),从而实现数据的压缩和降维。它由编码器(Encoder)和解码器(Decoder)两部分组成,编码器用于将图像信息降维并传入潜空间中,解码器将潜在数据表示转换回原始图像,而在潜在扩散模型的推理生成过程中我们只需用到 VAE 的解码器部分。
- ControlNet很强大,可以做文字嵌入。如果要控制用户的肢体,动作,服装风格等,可以用controlnet.
- LoRa也是必学的知识点,做微调用的技术方案.
- VAE也是必考知识点. VAE 的全称是 Variational Auto-Encoder,翻译过来是变分自动编码器,本质上是一种训练模型,Stable Diffusion 里的 VAE 主要是模型作者将训练好的模型“解压”的解码工具。
- Stabe Diffusion VAE的完整结构, 来自深入浅出完整解析Stable Diffusion.
SD VAE模型中有三个基础组件: GSC组件:GroupNorm+Swish+Conv Downsample组件:Padding+Conv Upsample组件:Interpolate+Conv 同时SD VAE模型还有两个核心组件:ResNetBlock模块和SelfAttention模型,两个模块的结构如上图所示。 SD VAE Encoder部分包含了三个DownBlock模块、一个ResNetBlock模块以及一个MidBlock模块,将输入图像压缩到Latent空间,转换成为Gaussian Distribution。 而VAE Decoder部分正好相反,其输入Latent空间特征,并重建成为像素级图像作为输出。其包含了三个UpBlock模块、一个ResNetBlock模块以及一个MidBlock模块。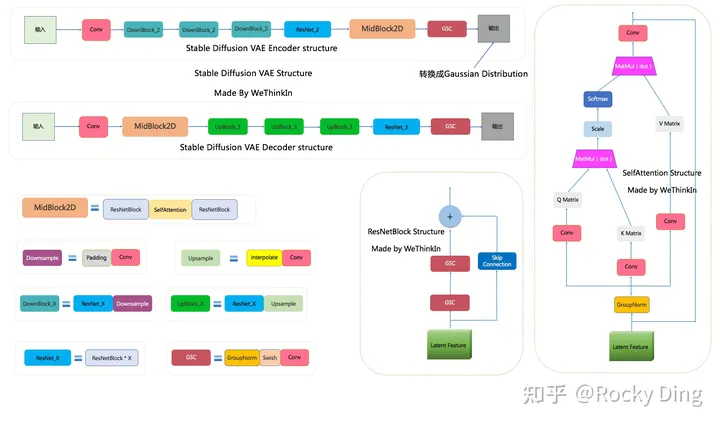
- 入门建议用WebUI
- 自动化用ComfyUI
- 做动画用Animate Diff
- Stable Diffusion 2出来了, The SD 2-v model produces 768x768 px outputs.
- 文本信息对图片生成的控制。SD模型在生成图片时,需要输入prompt提示词,那么这些文本信息是如何影响图片的生成呢? 答案非常简单:通过注意力机制。 在SD模型的训练中,每个训练样本都会对应一个文本描述的标签,我们将对应标签通过CLIP Text Encoder输出Text Embeddings,并将Text Embeddings以Cross Attention的形式与U-Net结构耦合并注入,使得每次输入的图片信息与文本信息进行融合训练。
- 深入浅出完整解析Stable Diffusion, 这篇文章技术深度很深,值得一读,强烈推荐!
- SD模型融合的形式,一共三种有如下所示:
- SD模型 + SD模型 -> 新SD模型
- SD模型 + LoRA模型 -> 新SD模型
- LoRA模型 + LoRA模型 -> 新LoRA模型
- SD模型融合的形式,一共三种有如下所示:
- 多模态领域的神器——CLIP(Contrastive Language-Image Pre-training),跨过了周期,从传统深度学习时代进入AIGC时代,成为了SD系列模型中文本和图像之间的“桥梁”。并且从某种程度上讲,正是因为CLIP模型的前置出现,加速推动了AI绘画领域的繁荣。CLIP主要的贡献就是利用无监督的文本信息,作为监督信号来学习视觉特征。原文
- 多模态机器学习,英文全称 MultiModal Machine Learning (MMML). 通常主要研究模态包括”3V”:即Verbal(文本)、Vocal(语音)、Visual(视觉)。
- 对齐Alignment. 从两种或多种不同的模态中识别(子)元素之间的直接关系。来自多模态学习
- 深入浅出聊聊stable diffusion原理, 英文原文.
- Stable Diffusion 超详细讲解, csdn. JarodYv写的系列文章非常值得一读.
- 多模态机器学习
- 多模态机器学习
- 图生图方法首先是由 SDEdit 所提出的。SDEdit可以应用于任何的扩散模型。因此我们在Stable Diffusion中也有了图生图的功能。
Stable Diffusion理论
- 发展进程: GAN->DDPM->Diffusion->Stable Diffusion
- Stable Diffusion 脱胎于 Diffusion 模型。深入浅出聊聊stable diffusion原理, 英文原文.
- Stable Diffusion 超详细讲解, csdn.
- Diffusion Model(扩散模型)的训练可以分为两部分:
- 正向扩散过程 → 为图像添加噪声。
- 反向扩散过程 → 去除图像中的噪声。
- 核心是U-Net,一种卷积神经网络,由弗莱堡大学计算机科学系开发,用于生物医学图像分 割。
- 该网络基于完全卷积神经网络
- 其架构经过修改和扩展,可以使用更少的训练图像来实现更精确的分割。使用 U-Net 架构,在现代(2015 年) GPU上分割 512 × 512 图像只需不到一秒钟的时间。
- U-Net 架构也已用于迭代图像去噪的扩散模型。
- 该技术是许多现代图像生成模型的基础,例如DALL-E、Midjourney和Stable Diffusion。
- 训练的结果是一个噪声预测器.
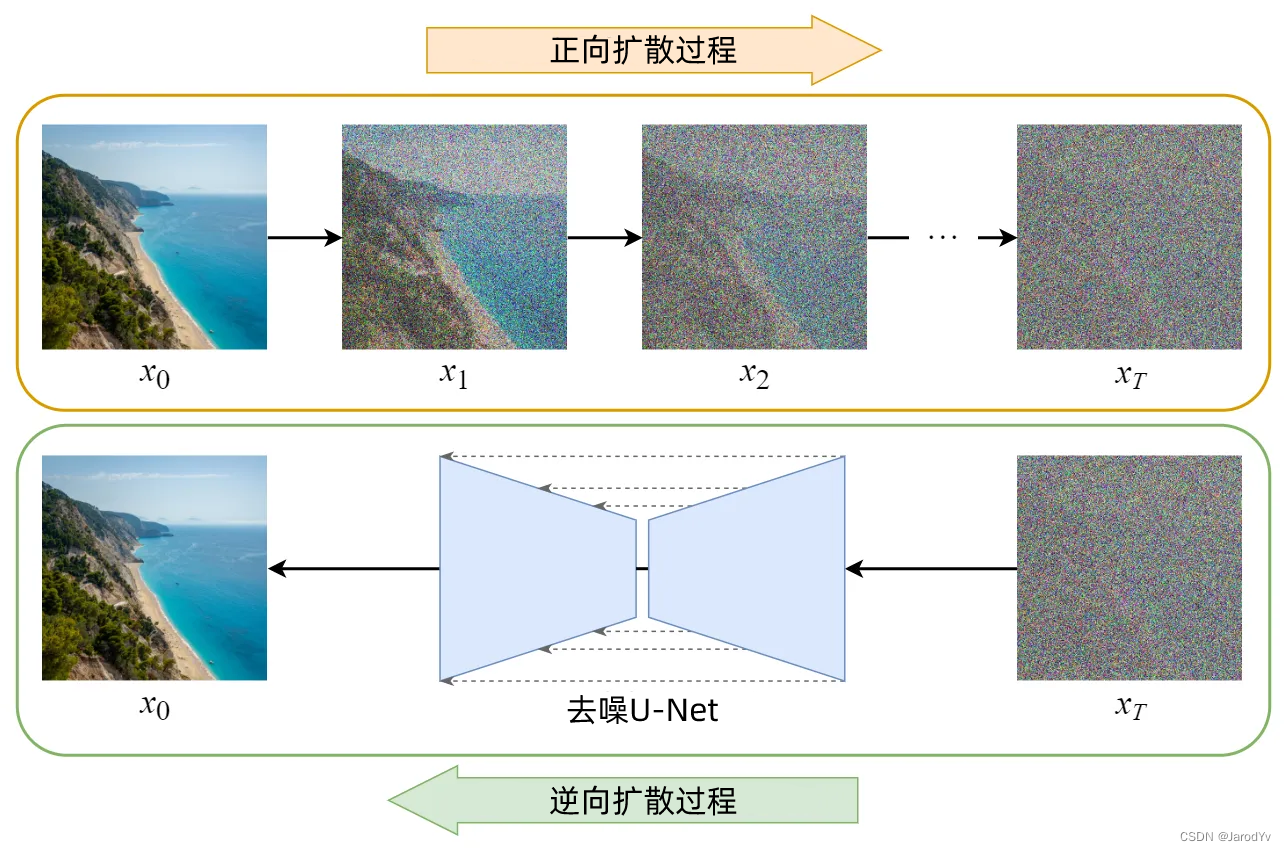
- Stable Diffusion和Diffusion最大的区别在于所有操作都在latent space(你可以理解为缩略图)完成的。
- Diffusion Model最大的问题是它的扩散过程是在图像空间中进行的,计算起来非常慢,你无法在任何单个GPU上运行,GMEM也吃不消。
- 稳定扩散(Stable Diffusion)是一种潜在扩散模型(Latent diffusion model),它不是在高维图像空间中操作,而是先将图像压缩到潜空间中,潜空间的大小只有原来的48分之一,因此它减少了需要处理的数据量,从而获得了更高的效率,这就是为什么它能运行得更快的原因。
- 增噪音是在缩略图里面完成的。
- 去噪音也是在缩略图里完成的。
- 一个核心的概念在于VAE, 通过VAE来把缩略图扩充到高精度图片。
- VAE的训练是通过原图和缩略图之间
- The latent space of Stable Diffusion model is 4x64x64, 48 times smaller than the image pixel space.
- Stable Diffusion can create images from 64×64 to 1024×1024 pixels, but optimal results are achieved with its default 512×512 size.
- 变分自编码器(Variational Autoencoder)
- 图像压缩解压缩是通过使用一种叫做变分自编码器(Variational Autoencoder)的技术来完成的。
- 提示词首先由CLIP标记器进行标记,CLIP是OpenAI 开发的深度学习模型,用于生成任何图像的文本描述,Stable DiffusionV1使用CLIP的标记器.
- Stable Diffusion Model 限制提示中使用75个标记(75标记不等于75个单词)
- 分词器只能对训练期间见过的单词进行分词。
- 嵌入(Embedding)是一个 768 值的向量。每个标记(token)都有自己唯一的嵌入向量。Embedding是由 CLIP 模型固定的,该模型在训练过程中学习得到。
## ControlNet
- 它是由斯坦福大学的Lvmin Zhang 和 Maneesh Agrawala 在2023 提出的
- ControlNet 是指一组使用稳定扩散精炼而成的神经网络,可在生成图像时实现精确的艺术和结构控制。它通过结合特定于任务的条件来改进默认的稳定扩散模型。
- 与传统的 Img2Img 技术不同,ControlNet 引入了一种突破性的途径来管理生成图像中的姿势、纹理和形状等元素, ControlNet 等模型的多功能性有助于应对不同的场景。
- 训练ControlNet官方教程
- ControlNet的5大模型
- Openpose, 控制人物姿势、手、表情
- Depth, 主要应用于对于场景的描绘还原,尤其是富有空间感的多层次场景。选择一个空间照片,选择任意一个带有depth的预处理器。depth也可以用来生成人物,尤其是那种肢体交叠,人体透视的场景。
- Canny, 用于边缘检测,需要还原外形的情景下,如果图像有一些需要精细表达的内容,也可以使用canny,它可以保证你的文字、标识不变形。如果使用canny的时候有些线条无法识别,尝试降低threshold数值,能将明暗差异不那么明显的部分线条识别进来。canny现在主要应用于线稿上色.
- SoftEdge(Hed)柔和边缘又叫做整体边缘线条检测,相较于canny精确的线条检测,softedge的检测更加柔和,会有更大的随机性,AI更大的发挥空间。
- Scribble(涂鸦)Scribble是一种更加随机的临摹,给AI充分的发挥空间。
LoRA
Ref
- 十分钟读懂Stable Diffusion
- Safetensors是什么文件?
- 汉字写身上
- 手把手教你用 SD 生成文字形状的光线,用来做营销宣传图非常有效
- https://www.haoshuo.com/article/64b52a4b83c8ec614b943468,【SD教程】文字光效制作完全指南,SD实现超炫文字效果
- https://zhuanlan.zhihu.com/p/635299852, ControlNet新玩法爆火:画出可扫码插画,内容链接任意指定
- https://y3if3fk7ce.feishu.cn/docx/QBqwdyde7omVf4x69paconlgnAc, AIGC从入门到精通教程汇总
- https://y3if3fk7ce.feishu.cn/docx/HjNrd25yDoV0LqxWpxwcEDsMnib, 时尚杂志封面prompt
- tps://exp-blog.com/ai/sd-ru-men-11-qrcode-logo/,「SD 零基础入门 11」ControlNet 进阶:打造炫酷的艺术字和二维码
- https://mp.weixin.qq.com/s/i4WR5ULH1ZZYl8Watf3EPw, SD 二维码原作者文章
- 中国传统纹样
- LoRA 训练流程:aigc.ioclab.com/sd-showcase/chinese-ornament
- LoRA 模型下载:civitai.com/models/29858/chinese-traditional-pattern
- https://aigc.ioclab.com/, SD 二维码作者组织写的一套入门文章
- 里面有怎么训练QR code LoRA模型的教程: https://aigc.ioclab.com/sd-showcase/chinese-ornament
- https://vladmandic.github.io/sd-extension-system-info/pages/benchmark.html, GPU测速列表
- https://www.uisdc.com/controlnet-2, controlnet和模型安装
- https://www.uisdc.com/stable-diffusion-21, 特效文字制作
- https://www.dongwm.com/post/stable-diffusion-vae/,怎么配置VAE(Variational Auto-Encoder)
- https://www.uisdc.com/stable-diffusion-3, VAE详解
- VAE 的全称是 Variational Auto-Encoder,翻译过来是变分自动编码器,本质上是一种训练模型,Stable Diffusion 里的 VAE 主要是模型作者将训练好的模型“解压”的解码工具。
- 这里可以切换 VAE。一般情况下我们就选择第一个自动就行了。
- controlnet models to folder C:\stable-diffusion-webui-docker\data\config\auto\extensions\sd-webui-controlnet\models
- ttps://github.com/Mikubill/sd-webui-controlnet,
- https://www.jinfz.com/thread-4006-1-1.html, controlnet详解各种参数
- ControlNet 作者:张吕敏,他是2021年本科毕业,目前正在斯坦福读博的中国人,
- https://zhuanlan.zhihu.com/p/640475200,LORA模型原理详解+分层控制使用
- https://www.yizz.cn/
- https://github.com/toriato/stable-diffusion-webui-wd14-tagger, 提示词反推
- https://www.luckydesigner.space/oh-my-god-how-to-use-stable-diffusion-to-create-porn-images/, 色图生成
- https://www.cnblogs.com/88223100/p/How-to-write-prompt-words-using-Stable-Diffusion.html, 怎么写提示词
- https://zhuanlan.zhihu.com/p/639488723, 用sd roop换脸
- 动手学深度学习, 全球大牛开源的教程,每课都有notebook可以试验.
模型收集及技巧
- https://civitai.com/models/6424/chilloutmix, 大名鼎鼎的亚洲美女模型。市面上你看到的大量的AI美女,基本上都是这个模型生成的。也正是这个模型,让AI绘画彻底出圈。然而,由于有人利用该模型从事网络诈骗行为,已经有骗子被网警抓进去了,因此吓得该模型的作者删库跑路。后来该模型免费赠送给了C站。目前该模型在C站仍可以继续下载,为18+,但由于该模型争议较大,因此不建议大家轻易下载使用,如果要使用,也请谨慎使用,不要用于非法的目的。
- sample:
head portrait, realistic, 1girl, eyes, loli, lots of frills, black long dress, starry sky, black hair blowing in the wind, trees, bloom light effect head portrait表示只画头部。
- sample:
- https://civitai.com/models/8281/perfect-world, 欧美版的Chilloutmix,主要绘制欧美风格的美女,不过偏2.5D,介于动漫和写实之间。产图基本默认NSFW,需要谨慎使用。
