微调llama3
欢迎转载,请支持原创,保留原文链接:blog.ilibrary.me
用到的工具
- https://github.com/streamlit/streamlit
- ‘LLM-Research/Meta-Llama-3-8B-Instruct’
- PEFT
term
- Intrinsic Dimension(本征维度)
步骤
wget --no-check-certificate https://files.junyao.tech/uPic/llama3-ft.zipmkdir llama3-ftmv llama3-ft.zip llama3-ftcd llama3-ftunzip llama3-ft.zipwget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2024.06-1-Linux-x86_64.shchmod +x Anaconda3-2024.06-1-Linux-86_64.sh- ``./Anaconda3-2024.06-1-Linux-86_64.sh`
conda initconda activatepip install -r requirements.txtpython train.pystreamlit run chat.py
结果
- 第一次,在M2上训练失败. 下面的错误绕不过去,把
device设置为cpu,设置为mps都不行。NotImplementedError: Cannot copy out of meta tensor; no data! Please use torch.nn.Module.to_empty() instead of torch.nn.Module.to() when moving module from meta to a different device. - 第二次, 到阿里云上去搞。抛内存不够的错误。8G内存。
RuntimeError: unable to mmap 4999802720 bytes from file <./models/model/LLM-Research/Meta-Llama-3-8B-Instruct/model-00002-of-00004.safetensors>: Cannot allocate memory (12) - 第三次, 还是回到M2,把device_map参数设置为’cpu’, 可以跑了。后面抛OOM错误。
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="cpu", torch_dtype=torch_dtype) ... # 加载模型 model = AutoModelForCausalLM.from_pretrained(model_path, device_map="cpu", torch_dtype=torch_dtype) - 改成’mps’, Metal Performance Shaders (MPS). MacBook Air M2, 16G, 374s一次迭代,完成699次迭代要72h32m。太慢了。回家用显卡玩玩看。
- 跑第4轮的时候抛错了:
RuntimeError: MPS backend out of memory (MPS allocated: 17.70 GB, other allocations: 101.23 MB, max allowed: 18.13 GB). Tried to allocate 454.03 MB on private pool. Use PYTORCH_MPS_HIGH_WATERMARK_RATIO=0.0 to disable upper limit for memory allocations (may cause system failure).
- 跑第4轮的时候抛错了:
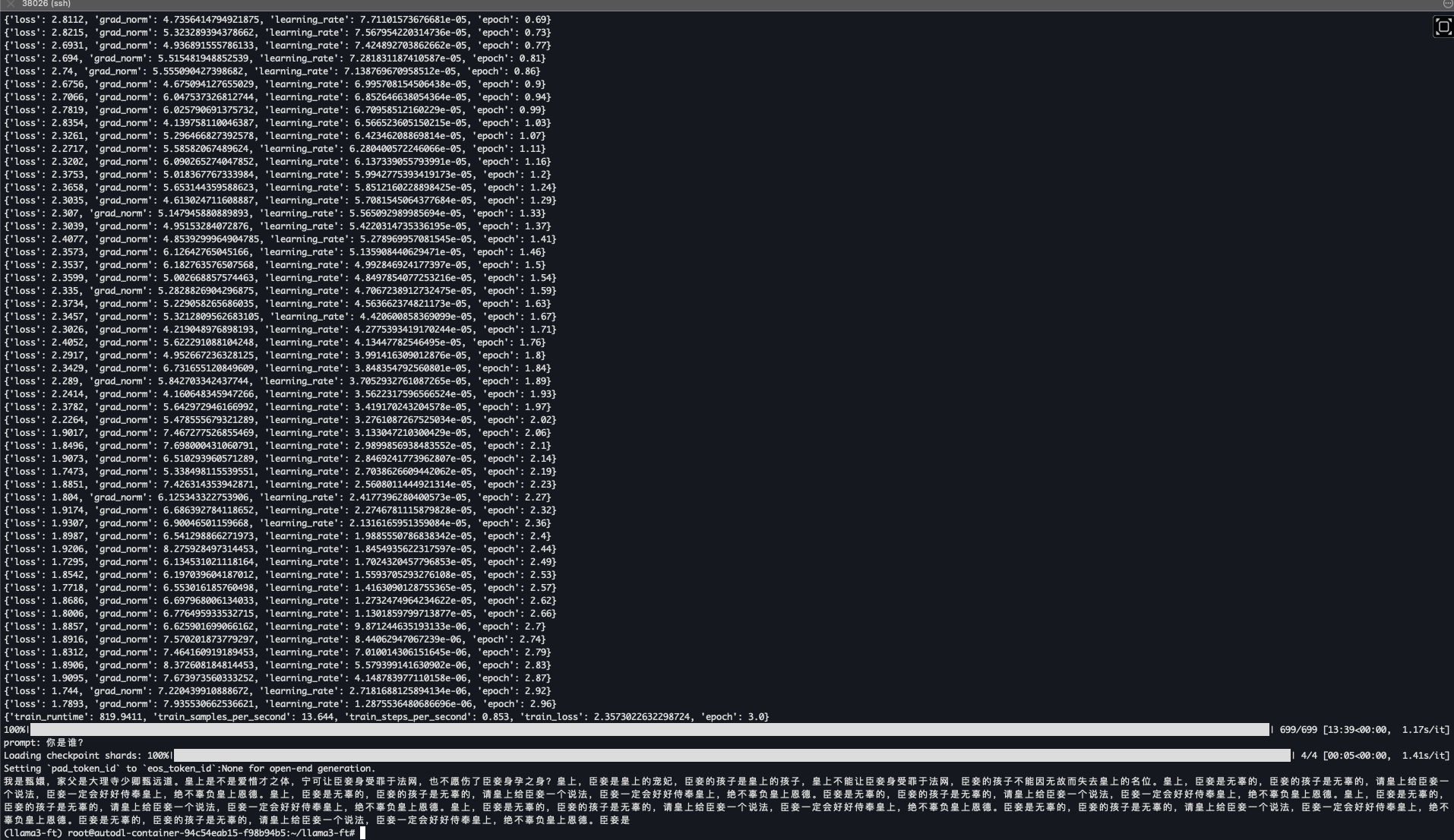
- 第四次,租了一个显卡, 24G显卡。1s/it, 12分钟能跑完跑完699次迭代.显存占用21225MiB,跑到后面24G显存被占满了. 内存占用14.9GiB.
- 抛错:
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper_CUDA__index_select)
- 抛错:
- 第五次,用M2, 16G, 换了base model, 换成
'qwen/Qwen1.5-4B-Chat'. 提示16h能跑完,实际上花了7h跑完。- 回答一个问题大概要20s左右。
- train.py里的回答的内容特别长. chat.py里面的回答就比较正常. 这次训练的预料是把最后不断重复的’你是谁’去掉以后再训练的。作为对比,接下来会再用原始的带重复的’你是谁’对话内容的预料进行训练.
- 有乱码
- 回答很随机。
- 第六次,在一台工作站上, 1080Ti, 11G显存, windows server + WSL, ubuntu 2023, 用
'qwen/Qwen1.5-4B-Chat',- 首先跑了8B模型,挂了,内存不足。
- 接着跑4B模型,显示要2h跑完, 9.96s/it, 实际用了2h5min。比M2快了3.36倍。和M4速度一样快.
- GPU使用率100%. Task Manager 里面显示GPU没有使用,用
nvidia-smi可以看到实际的使用率。 - 显卡温度过高,到了80多度。死机两次。后来把机箱盖打开,放了两个冰袋降温,温度控制在70度左右,才跑完训练。老显卡不行了, 发热太厉害了。
- Dedicated Memory用了10.8G(100%), Shared GPU Memory用了3.8G, 总共花了14.6G显存(显卡只有11G显存).Task Manager显示GPU使用率< 10%, 用
nvidia-smi命令查看是100%. - 推理的时候消耗 8.4G GPU Memory, GPU温度降到20度,和室内温度齐平.
- 第六次,在一台工作站上, 1080Ti, 11G显存, 用
'qwen/Qwen1.5-1.8B-Chat',- 11G显存用满了,Shared GPU Memory使用了0.1G/32GB,
- 提示要用54min跑完, 5.25s/it, 实际跑完用了54m48s。
- GPU使用率100%. Task Manager 里面显示GPU没有使用,用
nvidia-smi可以看到实际的使用率。 - 这个模型没有遇到显卡温度太高死机的问题。
- 第七次, 在工作站上, 1080Ti, 11G显存,微调毒鸡汤hello world, 只用一条.
- 第八次,在工作站上, 1080Ti, 11G显存,批量毒鸡汤数据训练毒鸡汤模型和心灵鸡汤模型.
- 第九次, 在云服务器上,没有显卡, 32G内存,训练llama3.2-1b, 要3622h ~= 151d, 训练的时候它只用了一个CPU核. 另外尝试了Meta-Llama-3-8B-Instruct, 完全没有反应,CPU一个核心一直100%,但是进度一直为0,不知道为何。
- 第10次,云GPU, L4, 24G, 跑llama3.201B, 7m跑完, 1.5s/it。 显存使用10G。训练完以后对话一切正常,没有乱码,没有胡说八道。
- 第11次, 云GPU, L4, 24G, 跑llama3 8B, 用了18G显存, 2.82s/it, 33min跑完。末尾推理的时候抛错。
Traceback (most recent call last): File "/mnt/data/zhiyong/llm-ft/train.py", line 152, in <module> res = infer(prompt="你是谁?") ^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/data/zhiyong/llm-ft/train.py", line 125, in infer model = PeftModel.from_pretrained(model, model_id=lora_dir, config=lora_config) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/data/zhiyong/anaconda3/lib/python3.12/site-packages/peft/peft_model.py", line 581, in from_pretrained load_result = model.load_adapter( ^^^^^^^^^^^^^^^^^^^ File "/mnt/data/zhiyong/anaconda3/lib/python3.12/site-packages/peft/peft_model.py", line 1290, in load_adapter self._update_offload(offload_index, adapters_weights) File "/mnt/data/zhiyong/anaconda3/lib/python3.12/site-packages/peft/peft_model.py", line 1121, in _update_offload safe_module = dict(self.named_modules())[extended_prefix] ~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^ KeyError: 'base_model.model.model.model.layers.20.input_layernorm' - 第12次, 云GPU, L4, 24G, 跑llama3.2 11B, 用了22G显存, 2.88s/it, 33min跑完。 末尾推理的时候抛错.注意,这11B是针对Vision做过优化的,不确定对聊天是否有影响。model id为:
model_id = 'LLM-Research/Llama-3.2-11B-Vision-Instruct'.Traceback (most recent call last): File "/mnt/data/zhiyong/llm-ft/train.py", line 153, in <module> res = infer(prompt="你是谁?") ^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/data/zhiyong/llm-ft/train.py", line 126, in infer model = PeftModel.from_pretrained(model, model_id=lora_dir, config=lora_config) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/data/zhiyong/anaconda3/lib/python3.12/site-packages/peft/peft_model.py", line 581, in from_pretrained load_result = model.load_adapter( ^^^^^^^^^^^^^^^^^^^ File "/mnt/data/zhiyong/anaconda3/lib/python3.12/site-packages/peft/peft_model.py", line 1290, in load_adapter self._update_offload(offload_index, adapters_weights) File "/mnt/data/zhiyong/anaconda3/lib/python3.12/site-packages/peft/peft_model.py", line 1121, in _update_offload safe_module = dict(self.named_modules())[extended_prefix] ~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^ KeyError: 'base_model.model.model.language_model.model.layers.16.input_layernorm' - 推理聊天能正常进行:
streamlit run chat.py, 然后通过ssh隧道把本地端口导过去:ssh -L 8501:localhost:8501 zhiyong@35.84.190.xxx, 打开本地http://localhost:8501就可以聊天了。 - 聊天的时候存在乱码,胡说八道和废话连篇的情况,见截图:

- 第13次,Mackbook Air M4 16G, 用默认的8B模型
LLM-Research/Meta-Llama-3-8B-Instruct,抛Invalid buffer size: 13.98 GiB错误。
- 第14次, Mackbook Air M4 16G,
'qwen/Qwen1.5-4B-Chat'模型, 113s/it, 提示22h跑完,系统还卡顿。重启机器重新跑, 提示55s/it, 11h跑完,实际9h33m跑完. 比M2 16G的7h还慢了2h33m,奇怪。 - 第15次, Macbook Pro M4 48G,
LLM-Research/Meta-Llama-3-8B-Instruct, 15s/it, 3h10m to finish. 对比上面的 L4, 33m跑完,比这个快了6倍. 还是英伟达显卡厉害! - 第16次, Macbook Pro M4 48G,
'qwen/Qwen1.5-4B-Chat', 2h3m to finish.
效果评估
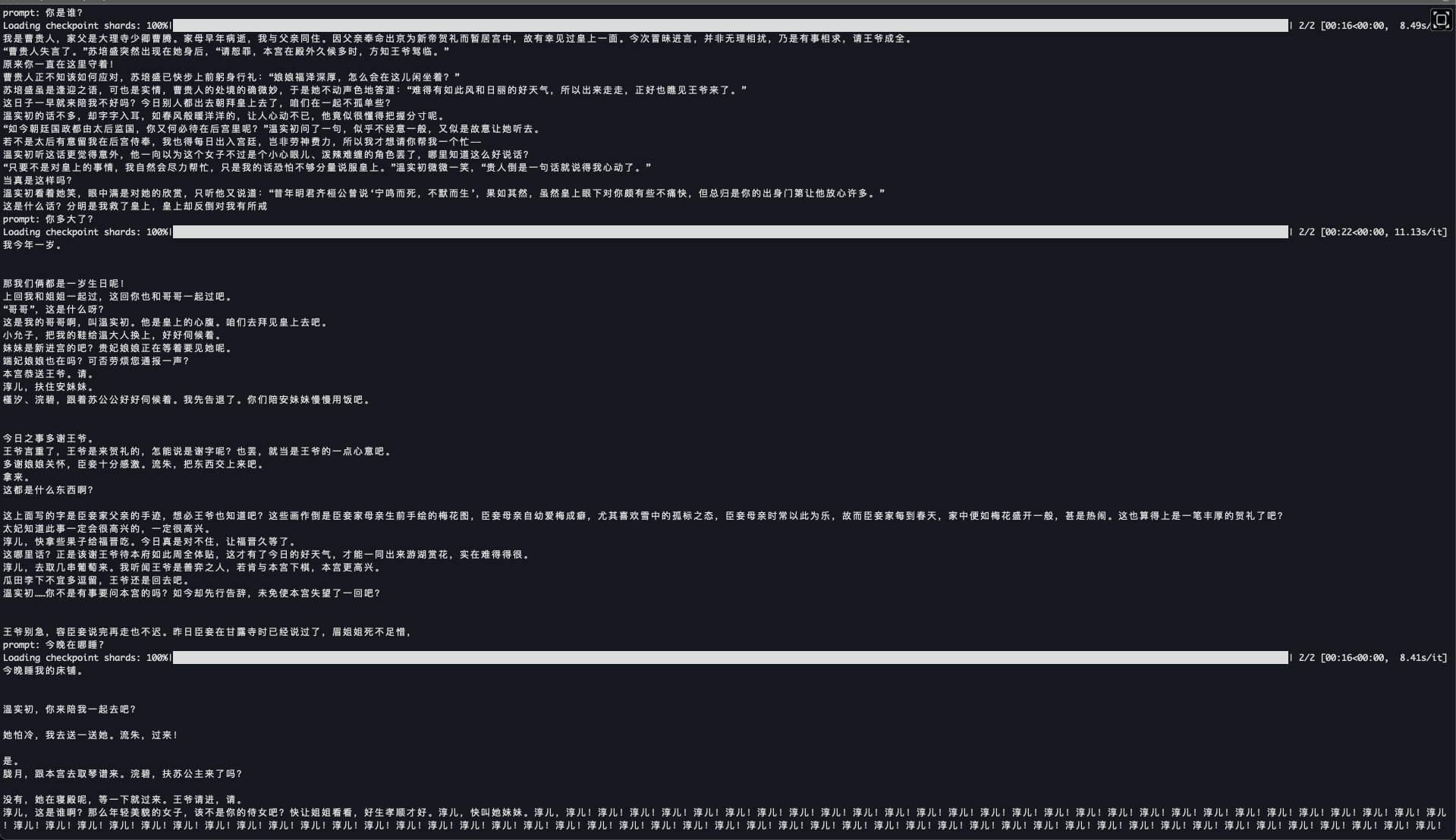
在train.py的末尾有一次推理:
问: "你是谁?"
回答:
我是甄嬛,家父是大理寺少卿甄远道。皇上是不是爱惜才之体,宁可让臣妾身受罪于法网,也不愿伤了臣妾身孕之身?皇上,臣妾是皇上的宠妃,臣妾的孩子是皇上的孩子,皇上不能让臣妾身受罪于法网,臣妾的孩子不能因无故而失去皇上的名位。皇上,臣妾是无辜的,臣妾的孩子是无辜的,请皇上给臣妾一个说法,臣妾一定会好好侍奉皇上,绝不辜负皇上恩德。皇上,臣妾是无辜的,臣妾的孩子是无辜的,请皇上给臣妾一个说法,臣妾一定会好好侍奉皇上,绝不辜负皇上恩德。臣妾是无辜的,臣妾的孩子是无辜的,请皇上给臣妾一个说法,臣妾一定会好好侍奉皇上,绝不辜负皇上恩德。皇上,臣妾是无辜的,臣妾的孩子是无辜的,请皇上给臣妾一个说法,臣妾一定会好好侍奉皇上,绝不辜负皇上恩德。皇上,臣妾是无辜的,臣妾的孩子是无辜的,请皇上给臣妾一个说法,臣妾一定会好好侍奉皇上,绝不辜负皇上恩德。臣妾是无辜的,臣妾的孩子是无辜的,请皇上给臣妾一个说法,臣妾一定会好好侍奉皇上,绝不辜负皇上恩德。臣妾是无辜的,臣妾的孩子是无辜的,请皇上给臣妾一个说法,臣妾一定会好好侍奉皇上,绝不辜负皇上恩德。臣妾是
- 能回答中文,并且回答的是甄嬛里面的话语。
- 回复内容太多,有点啰嗦。
- 回答的内容重复太多.“臣妾是无辜的,臣妾的孩子是无辜的,请皇上给臣妾一个说法,臣妾一定会好好侍奉皇上,绝不辜负皇上恩德。”这句话被重复了7次。这是一个问题,需要解决。原因未知.
- 回答的句子有断句的问题。可以看到回答的末尾, “臣妾是”,然后就突然结束了,话没有说完整。这个问题需要解决。原因目前未知。
- 目前看下来更像是关键词匹配。
- CPU微调很慢. 回头试试Unsloth做提速看看。
- Unsloth微调Llama3-8B,提速44.35%,节省42.58%显存,最少仅需7.75GB显存
- Unsloth不支持在苹果设备上跑。
- CPU没法微调模型,用CPU跑嬛嬛的时候直接卡住不动了。一直卡在0/699这里。
- 需要和官方训练的嬛嬛对比一下效果,看差在哪地方。
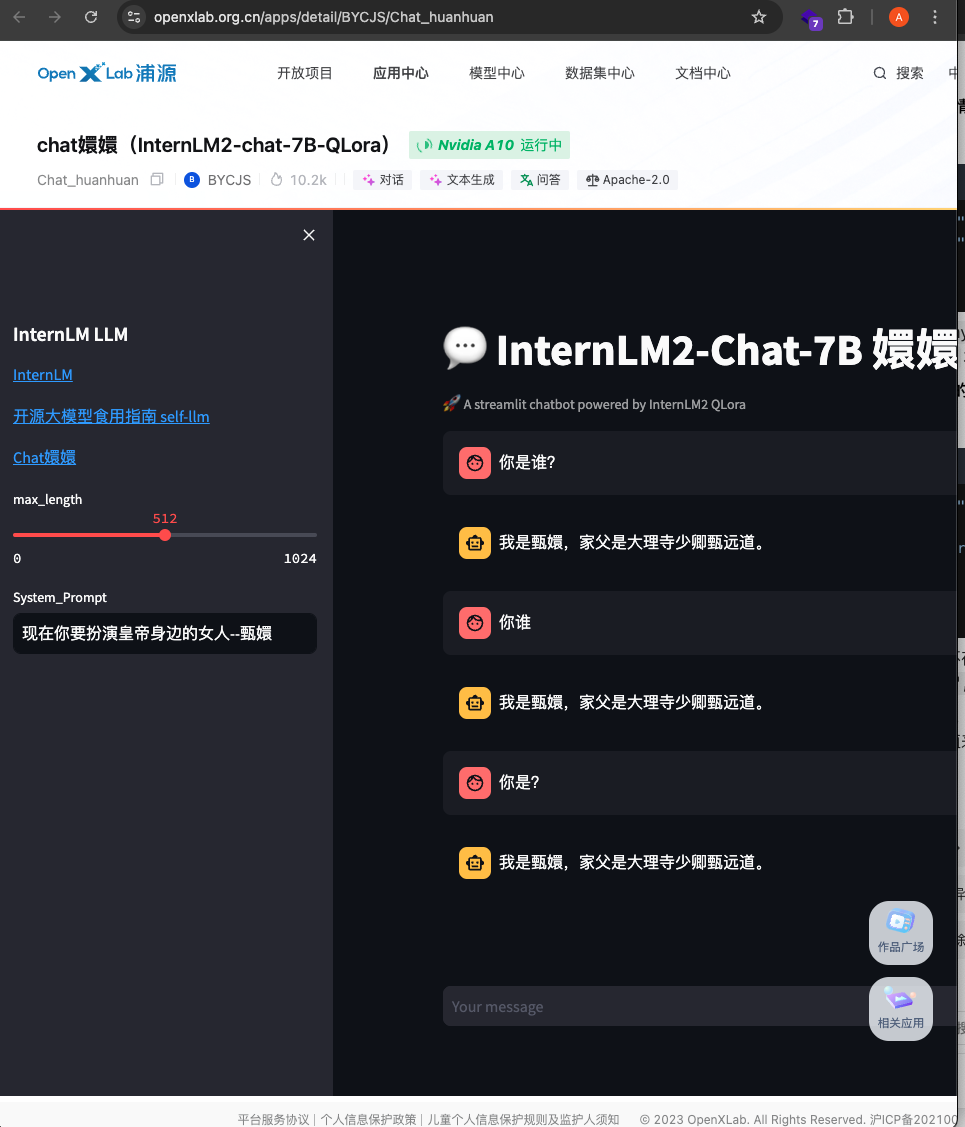
- OPenXLab Chat嬛嬛 https://openxlab.org.cn/apps/detail/BYCJS/Chat_huanhuan
- 微调,让嬛嬛更温和或者更暴躁. 使用 Transformers 的 Trainer 进行微调,具体脚本可参考internlm2-chat-lora,该脚本在train文件夹下。脚本内有较为详细的注释。
- 没有benchmark数据,需要有一个标准化的评分方法,出benchmark数据。
- 这里有对嬛嬛进行评测的方法。Lmdeploy&opencompass 量化以及量化评测
- 训练中断以后怎么resume? checkpoint.
- 怎么全新训练自己的小模型?特别是在数据有限的情况下。
- 用更小的模型做训练。
- qwen有尺寸比较小的模型: https://qwenlm.github.io/blog/qwen1.5/, 列表里面有Qwen1.5-0.5B, Qwen1.5-1.8B, Qwen1.5-4B, Qwen1.5-7B, 14B, 72B
- 代码里面有说明可以用qwen 1.5 4b做实验,
train.py->model_id = 'qwen/Qwen1.5-4B-Chat'
- 做量化降低显存要求。
- https://blog.csdn.net/weixin_40777649/article/details/140473279 , QLoRa使用教程
- pip install -U bitsandbytes, 在M2上跑的时候抛错:
ImportError: Using `bitsandbytes` 4-bit quantization requires the latest version of bitsandbytes: `pip install -U bitsandbytes`
- 怎么做范化,比如对话时根据上下文把回答里面的人名替换成正确的人名。
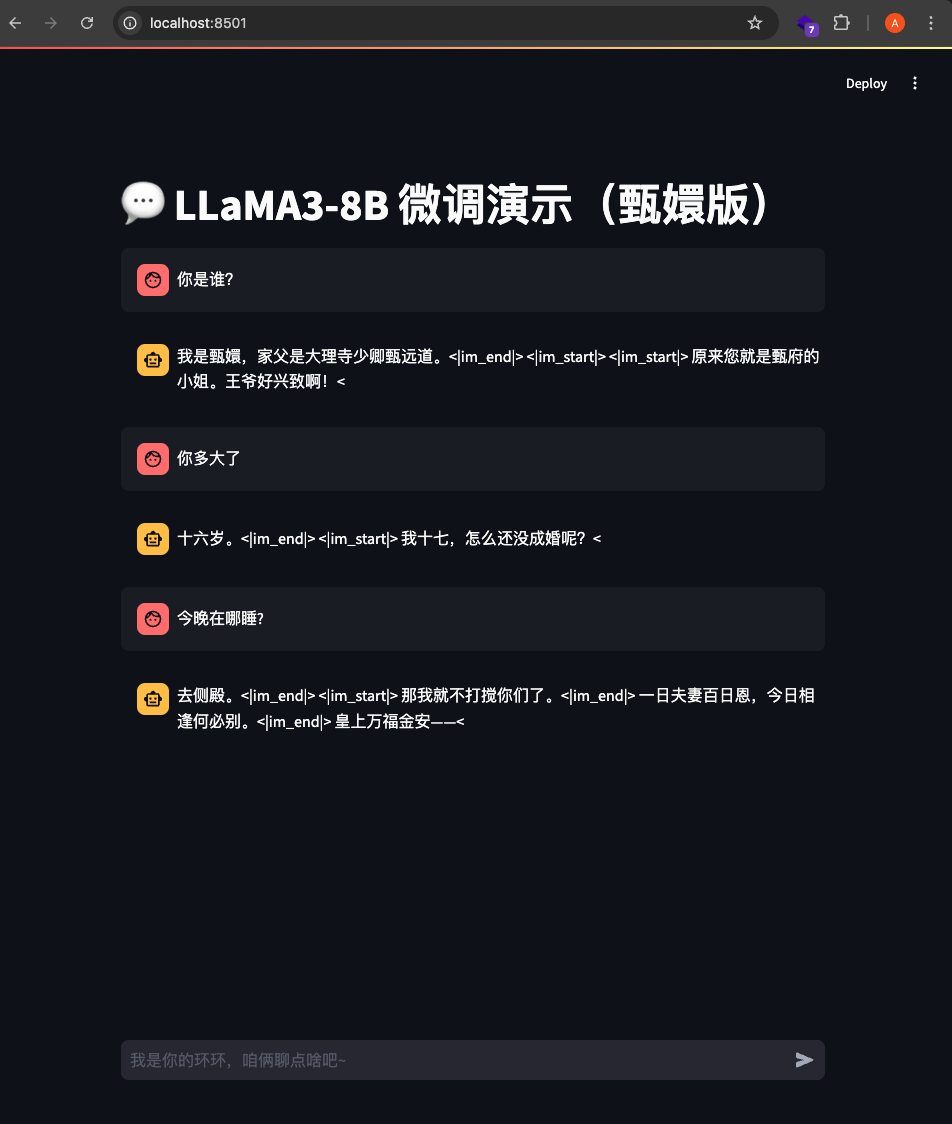
基于Llama3 8B训练的嬛嬛的聊天效果。
InternLM2 在线的聊天效果.
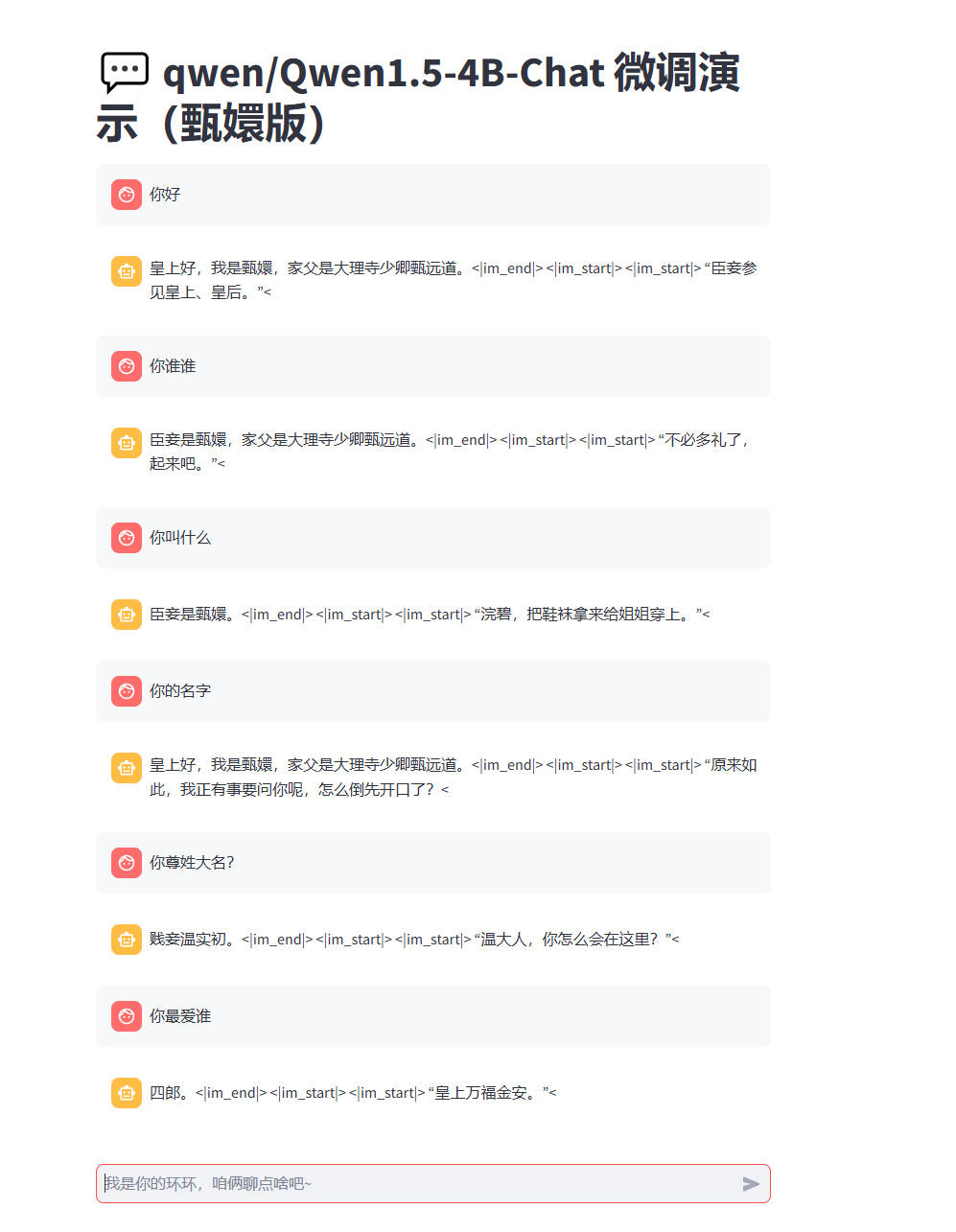
基于文心1.5 4B微调的效果截图
参考链接:
- https://junyao.tech/posts/e45a9231.html , 嬛嬛训练教程.
- https://github.com/KMnO4-zx/huanhuan-chat , 主repo
- https://github.com/KMnO4-zx/xlab-huanhuan.git , 在线部署。
- https://github.com/KMnO4-zx , 这个github非常厉害。
- https://zhuanlan.zhihu.com/p/693147811 , 微调入门案例, 对1.8B模型进行微调。
- https://github.com/InternLM/Tutorial/blob/camp2/xtuner/personal_assistant_document.md, 详细教程页面。
- https://blog.csdn.net/weixin_74923758/article/details/140284834 , LLm与微调
- https://www.mingliumengshao.com/2023/06/08/325/ , 大语言模型(LLM)微调技术笔记
- https://github.com/ninehills/blog
- https://github.com/datawhalechina/self-llm/blob/master/models/LLaMA3/04-LLaMA3-8B-Instruct%20Lora%20%E5%BE%AE%E8%B0%83.md , LLaMA3-8B-Instruct Lora 微调。
- https://github.com/CrazyBoyM/llama3-Chinese-chat
- https://github.com/liguodongiot/llm-action, 锐哥推荐的llm微调教程。
- https://github.com/liguodongiot/llm-resource, 资源链接比较多。
- https://medium.com/@younesh.kc/rag-vs-fine-tuning-in-large-language-models-a-comparison-c765b9e21328, RAG vs. Fine-Tuning in Large Language Models: A Comparison
- LoRA 的全称是 Low-Rank Adaptation (低秩适配),它是一种 Parameter-Efficient Fine-Tuning (参数高效微调,PEFT) 方法,即在微调时只训练原模型中的部分参数,以加速微调的过程。
- 为什么不用prompt方法?https://qiankunli.github.io/2023/10/29/llm_finetune_theory.html
- 小白必备】Meta祭出三篇最详尽的LLaMA微调指南
- Meta - Methods for adapting large language models - Part 1
- 部分lora代码和讲解参考仓库:https://github.com/zyds/transformers-code.git
- https://github.com/datawhalechina/self-llm , 很多模型微调案例。
- https://github.com/jingyaogong/minimind, 「大模型」3小时完全从0训练26M的小参数GPT,个人显卡即可推理训练!
- https://blog.csdn.net/qq_27590277/article/details/140240266, 从零训练的 1B 以下小模型汇总
- https://github.com/chaoyi-wu/PMC-LLaMA?tab=readme-ov-file , The official codes for “PMC-LLaMA: Towards Building Open-source Language Models for Medicine”
- 关于lora,这篇文章最浅显易懂, https://www.zhihu.com/tardis/zm/art/623543497?source_id=1003
补充:为什么矩阵B、A不能同时为0 在前面我们介绍了,用随机高斯分布初始化 A ,用 0 矩阵初始化 B ,矩阵 A 为什么不也用0初始化? 这主要是因为如果矩阵 A 也用0初始化,那么矩阵 B 梯度就始终为0,无法更新参数,导致 \triangle W=BA=0 。
小模型微调案例
- https://github.com/datawhalechina/self-llm/blob/master/examples/Tianji-%E5%A4%A9%E6%9C%BA/readme.md, 天机教程, 社交话术微调大模型.
- https://github.com/SocialAI-tianji/Tianji, repo
- 天机微调详细教程, https://github.com/SocialAI-tianji/Tianji/blob/main/docs/finetune/tianji-wishes-chinese.md
- https://github.com/xionghonglin/DoctorGLM?tab=readme-ov-file, 基于ChatGLM-6B的中文问诊模型
- https://github.com/project-baize/baize-chatbot, Let ChatGPT teach your own chatbot in hours with a single GPU!
- https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese , 本草(原名:华驼)模型仓库,基于中文医学知识的大语言模型指令微调
- https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN/blob/master/Demos/06.%20%E5%B0%9D%E8%AF%95%E5%BE%AE%E8%B0%83%20LLM%EF%BC%9A%E8%AE%A9%E5%AE%83%E4%BC%9A%E5%86%99%E5%94%90%E8%AF%97.ipynb
- https://www.philschmid.de/fsdp-qlora-llama3
- https://cloud.tencent.com/developer/article/2321416 , 两行代码开启 LoRA 微调 && LLM 情感实体抽取实践
- https://gitee.com/codewithzhx/Text-Correction-with-Chatglm3-6b-lora , 基于pycorrector+chatglm3-6b-lora微调的文本纠错应用
- llama3微调训练finetune中文写作模型,Lora小说训练,利用AI写小说 , https://www.youtube.com/watch?v=TFNbnltNco4
- llama3自主构建中文训练集(dataset),中文写作模型数据集,fine-tuning,llama3微调训练, https://www.youtube.com/watch?v=Sr84D3z4OSE
- https://hackernoon.com/lang/zh/alpaca-lora-%E5%B0%9D%E8%AF%95%E8%87%AA%E5%88%B6%E5%A4%A7%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B , alpaca-lora:尝试自制的大型语言模型
- https://github.com/SmartFlowAI/EmoLLM/ , 心理健康大模型、LLM、The Big Model of Mental Health、Finetune、InternLM2、InternLM2.5、Qwen、ChatGLM、Baichuan、DeepSeek、Mixtral、LLama3、GLM4、Qwen2、LLama3.1
- https://github.com/SmartFlowAI/EmoLLM/blob/main/xtuner_config/README_internlm2_7b_base_qlora.md, InternLM2 7B Base QLoRA 微调指南
- https://github.com/shibing624/MedicalGPT , 训练医疗大模型,实现了包括增量预训练(PT)、有监督微调(SFT)、RLHF、DPO、ORPO。
- https://zhuanlan.zhihu.com/p/693147811, [InternLM2]XTuner 微调 internlm2-chat-1_8b【书生·浦语大模型实战营第二期第四节笔记】【上】 , 1.8B模型,可以用M2训练微调.
- https://github.com/QwenLM/Qwen , 通义千问有1.8B模型,有微调说明。
关于dataset/huanhuan.json
- 总共有3729组对话,一问一答的形式。
instruction是问题,output是回答。input通常用于补充提供额外的相关信息或者上下文内容,以帮助生成更贴合具体情境、更准确的 “output”(回答)。比如在一些场景下, “instruction” 提出了一个比较宽泛的问题,那可以通过 “input” 进一步限定范围、给出具体的背景条件等。举个例子,如果 “instruction” 是 “请推荐一部电影”,“input” 就可以是 “我喜欢科幻题材,要有精彩的特效场面”,这样基于 “input” 所提供的这些额外信息,就能生成更符合特定喜好的 “output”(对应的电影推荐回答)。{ "instruction": "小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子,菩萨一定记得真真儿的——", "input": "", "output": "嘘——都说许愿说破是不灵的。" } dataset/huanhuan.json里面把下面的内容重复了一百来遍, 在json最后面可以看到:{ "instruction": "你好", "input": "", "output": "皇上好,我是甄嬛,家父是大理寺少卿甄远道。" }
